
NVIDIA CUDA · NPU · IA no seu hardware
IA que trabalha na sua máquina, com os seus dados
Ajudamos pequenas empresas em Campinas a usar IA local de forma prática — sem dependência de nuvem e sem complexidade desnecessária.
O que oferecemos
Três formas de começar com IA local
Cada serviço começa de onde a sua equipe está agora. O ritmo é definido por você.

Consultoria NPU Essencial
Uma conversa calma sobre se a IA local com o novo NVIDIA NPU faz sentido para o seu dia a dia. Começamos pelas suas prioridades e mapeamos possibilidades reais — sem compromisso de adesão.
- Sessão de diagnóstico do ambiente
- Relatório com possibilidades documentadas
- Orientação sobre onde o NPU pode ou não se aplicar
Parceiro de Tarefa CUDA
Configuramos uma tarefa de IA útil no hardware NVIDIA CUDA, alinhada a uma rotina que a sua equipe já conhece. Explicamos cada passo e permanecemos próximos enquanto as pessoas se familiarizam.
- Configuração completa no seu hardware
- Walkthrough presencial com a equipe
- Um mês de suporte pós-configuração

Plano de Integração IA Local
Um programa completo e sem pressa que traz CUDA e NPU para várias áreas do negócio — enquanto os dados permanecem nas suas máquinas. Trabalhamos gradualmente e nos adaptamos à sua equipe.
- Planejamento e rollout por fases
- Treinamento da equipe incluído
- Suporte contínuo pós-implantação
Por que a Tupã
O que diferencia uma abordagem local
IA no seu próprio hardware muda o que é possível — e o que é seguro.
Dados que não saem da empresa
O processamento acontece no hardware da própria empresa. Informações de clientes, finanças e processos internos não passam por servidores externos.
NVIDIA CUDA e NPU de nova geração
Usamos as capacidades de processamento paralelo do CUDA e a eficiência energética do NPU para tarefas de IA que rodam com baixa latência no local.
Ritmo definido pela sua equipe
Não existe calendário rígido. Avançamos conforme o conforto da equipe cresce, com revisões frequentes e ajustes no caminho.
Custo previsível, sem assinaturas
Sem mensalidades de API ou surpresas em faturas de nuvem. O investimento é pontual e os modelos ficam rodando localmente após a configuração.
Explicação em cada passo
Cada configuração é acompanhada de uma explicação clara. Você não precisa depender de nós para entender o que está rodando na sua infraestrutura.
Para pequenas empresas, de verdade
Não adaptamos soluções corporativas. Nossos serviços foram pensados para negócios que têm uma equipe pequena e precisam de resultados práticos, não de projetos longos.
Próximo passo
Quer entender se faz sentido para o seu negócio?
Começa com uma conversa. Você explica como sua empresa trabalha e nós mostramos onde o processamento local de IA pode ou não ajudar — sem compromisso.
Dúvidas frequentes
Perguntas comuns sobre IA local
O que é exatamente o processamento local com NVIDIA CUDA e NPU?
Minha empresa precisa de hardware especial para começar?
Quanto tempo leva para ver resultados práticos?
Meus dados ficam realmente protegidos sem ir para a nuvem?
A equipe precisa ter conhecimento técnico em IA?
Como funciona o suporte após a configuração?
Localização
Nossa sede em Campinas
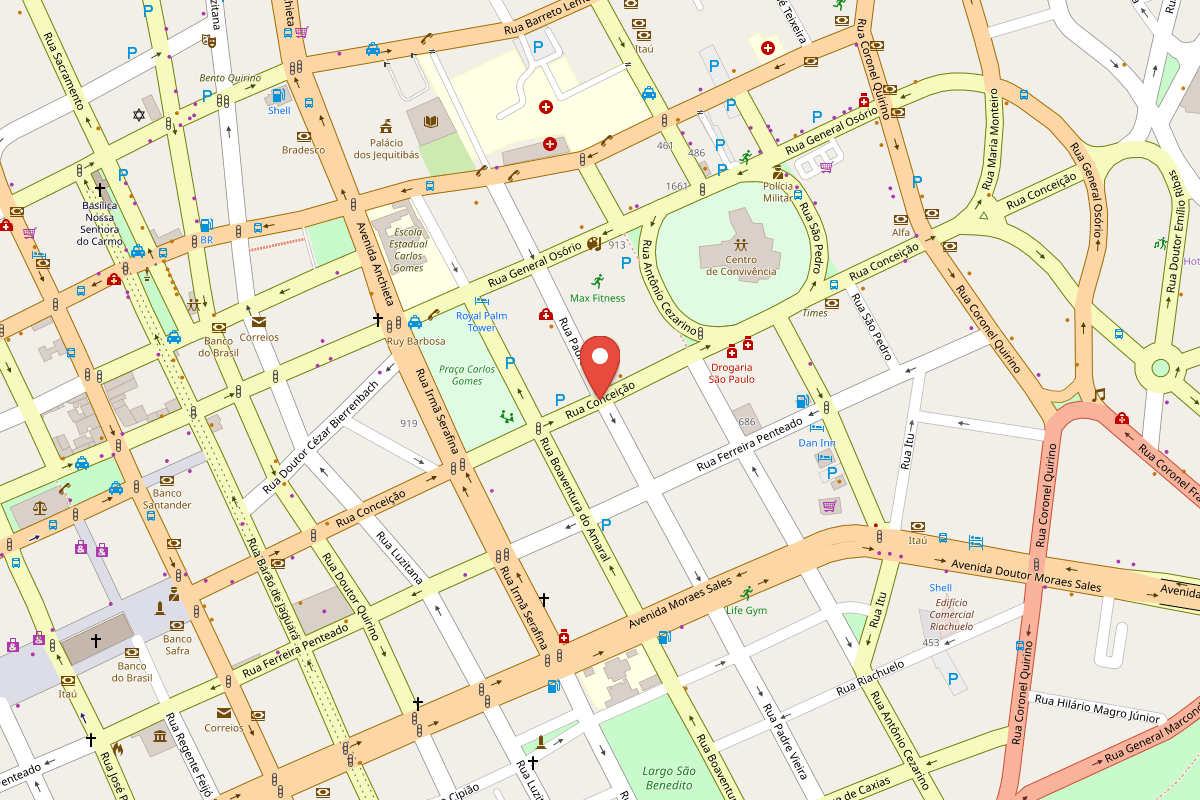
Rua Conceição 627, Centro, Campinas — SP, 13010-916
Contato
Entre em contato
Preencha o formulário ou use um dos canais abaixo. Respondemos dentro de um dia útil.
Informações de contato
Telefone
+55 19 99427-6183Endereço
Rua Conceição 627, Centro
Campinas — SP, 13010-916
Horário de atendimento
Segunda a sexta: 9h às 18h
Sábado: 9h às 13h
Nota sobre privacidade
As informações enviadas neste formulário são usadas apenas para retornar o seu contato. Não compartilhamos dados com terceiros.